Creating invoice + making payment is slower and slower #1506
Comments
|
It could be the number of payments on Alice, not just the number of invoices on Bob. |
|
Ok so to check this, I create 3 differents Alice instead of 3 concurrent payment by the same Alice:
There seems to have also some contention for in the case of 3 payments of the same Alice at same time costing around 100 ms. It seems there is indeed improvement, but I am surprised it is not a 3 times improvement. I would have expected the slope to get 3 times slower. |

|
Slope: Alice pays Bob: 2495 |
|
Possibly the remaining part is Bob getting overloaded, too. Hence not the three times improvement. Invoice payment lookup should be O(log n), but payment lookup is probably much less efficient (not as certain, I am more familiar with the invoice side than the payment side, despite practically writing the current If you are doing multiple Lines 75 to 92 in 11ca729 |
|
is there a way to purge this data? |
|
The linear list above is purged when a payment resolves: everything waiting for the payment to resolve is remove from the list, leaving only the payments that have not resolved yet. However there is still a database table on-disk that contains payments, and is also looked up when a payment resolves (succeeds or fails). The database table has an index on the We would do better with concrete profiling information, though --- would that be possible to provide? |
|
What do you mean by "waiting payment to resolve"? I am not only creating invoice here, I am also paying them. |
|
I am creating a project to easily benchmark some scenaris https:/dgarage/LightningBenchmarks (it will also support other implementation) though GCC profiling would give better idea about particular code causing real issues. I can include it in the list of generated artefact. |
|
The Payments are resolved if they are known to have succeeded, or known to have failed or timed out. Note that in C-lightning, a "payment" is an object on the payer that tracks an individual payment attempt (an attempt at getting the preimage for a payment hash in exchange for an amount), while an "invoice" is an object on the payee that has a preimage and its hash and which is resolved when it releases the preimage in exchange for receiving money. So when I say "waiting for payment to resolve" I mean an object on the payer that is waiting for the routed payment to return a success or failure. |
|
Yes but what I don't undesrtand is that this list of awaiting payments should be purged when |
|
I probably need to audit the database tables then... maybe we forgot to index something we are using as key in that table. We are also using raw 32-byte blobs as keys in the database table, so maybe SQLITE does not handle those well... |
|
@NicolasDorier I've just done similar rudimentary test with So as @ZmnSCPxj says this may likely be problem with indexing or something similar that increases search time as number of transactions grow. |
|
@cdecker suggested I use perftrace to find out where is the issue. I will do during next week. I never used it though, so if someone can give me pointer it would help me a lot. |
|
@NicolasDorier quick question, does Bob perform any |
|
no |
|
Ok so I managed to get more info in the stack traces. Sadly I don't think it help.
If the issue is related to IO, would we see it in those graphs? I would assume we won't as the calls are asynchronous. |
|
Looks like a good part is logging. Hmm. That and |
|
I am wondering if this is the full picture. Because when you do a request to the DB, I don't think you block the thread so it would not show on the flamegraph, but it would still make the call slow. |
|
We are using sqlite3, which to my understanding has its code execute in the same process as the caller. All our db calls block rather than have a result callback. |
|
Trying to have more data point... running the script for longer taking flamegraph along the way... hopefully we can also see what is taking more and more time. |
|
I am concerned also about why I don't see any call trace in |
|
I let it run for like 10-15 minutes. At beginning (Alice1 and Bob1) 7 concurrent payments took 700ms, at the end (Alice3 and Bob3) took 3 seconds. By opening the traces of different tab of the browser and switching via CTLR+TAB you can see the evolution over time Bob1, Bob2, Bob3 or Alice. I am disappointed. While Also, why I can't see any call to the RPC methods? |
|
The logging subsystem was never this taxing in any of my traces, that's surprising. Is the same true if you redirect to What bothers me is that the |
|
Yes, that surprise me as well. I will turn off logging and run again. (was debug) |
|
I am using |
|
Ok so, using My CPU and IO is mainly unused. Log stuff are still taking lot's of time. I am running I will also remove Those are the last traces... and they are pretty boring, almost similar to previous one, with a bit less time on logging. Will continue tomorrow... |
|
Ok. So I can't really remove However, I refactored my code to limit the number of time I connect to a socket.
I still present my finding here: The linear issue outlined is still unsolved. I let Alice and Bob mind their own business for 30 minutes while taking a flamegraph every 5 minutes. My finding are: Logs functions are suspiciously taking way more time than they should, even though I run with
I could not pin point any big issues aside #1518
Also, huge amount of time is spent in I have still not identified the linear time issue. Here are the latest flamegraphs I ran. |

|
|
|
I am using alpine3.7 with some hacks for glib compat. |
|
|
|
However still consistent increase... tried to run those tests on a separate VM in case it was my PC's issue but no luck, same result.
|

|
We create a number of child processes: Perhaps some library is using threads or processes under-the-hood. But in any case it seems we will not get any information from the The fact that the concurency=1 still has a slight slope implies some of the time is spent in some linear search of all payments or invoices. |
|
I suddenly remembered that we also |
|
If so, why do you call |
|
I am starting to wonder if the reason I don't find anything relevant increasing in the flamegraph is because the slowdown is coming from inside the (Tried also to run flamegraph on idle Alice, no __clone) |
|
@ZmnSCPxj I inserted a printf to see all bitcoin-cli commands. This is not the problem, no command is sent during the run. |
|
I throw in the sponge. Let me know if I can try anything else to find out more info. Feel free to close this issue except if you have idea where I can dig more about this. |
|
Okay. I will try to find some time to analyze your gathered data in detail. This makes me wonder if there are some threads going on in the background in some library we are using; I begin to suspect sqlite3. Hmm. |
|
is there a way to hook |
|
Tried to take a look with htop while it is running hoping to find more. I don't think I can see the threads correctly with |
|
I just don't understand... I added a breakpoint through gdb on |
|
It is possible that the perftrace gets confused with regards to OS calls. OS calls might be using a completely separate stack, for example, so it appears to root from the original Interesting tidbit is lightning/ccan/ccan/timer/timer.c Line 198 in 8d64145 Another thing fatter in So it seems to me that a good part of the delay on Alice is indeed logging due to the Indeed, under |
|
So it seems that we can gain some nice improvement by filtering log at the child level instead of reporting back to I noticed with |
|
Left column Alice, Right Bob. Vertical time (every 5 minutes) Full resolution on https://aois.blob.core.windows.net/public/CLightningBenchmarkResults/traces.jpg |
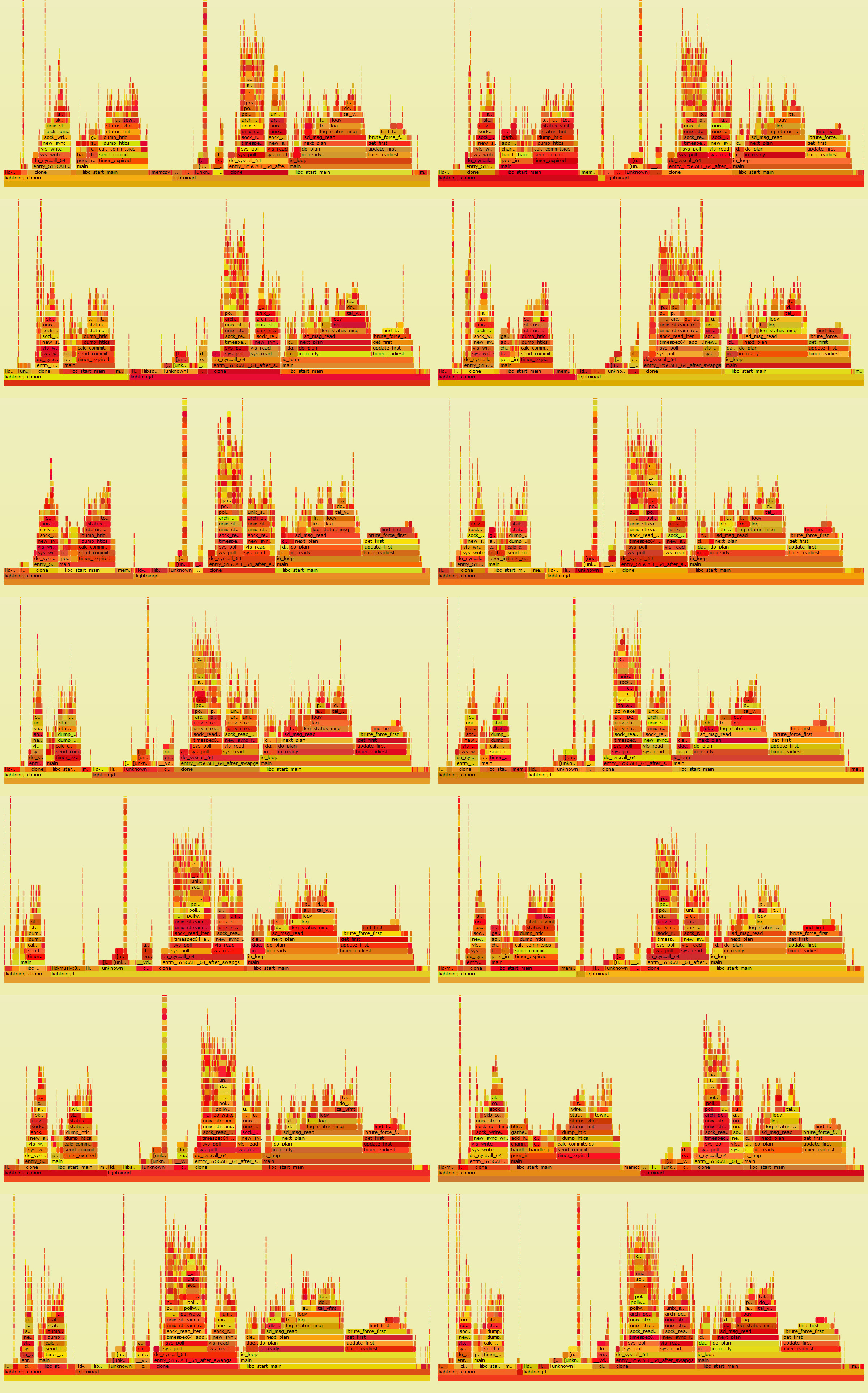
|
Raw data on all the tests I did. |
|
lightning/channeld/full_channel.c Lines 95 to 124 in 7f43771 |
|
Thank you @Saibato, that is probably indeed the cause of the linear increase of processing time proportional to the number of payments done in parallel. Probably the best thing to do in response is to propagate the loglevel to daemons somehow, and to suppress call to |
|
Filtering at subdaemon level is not a good idea, actually. |
|
Will try today sorry for the delay! |
|
@Saibato it worked. I just commented |
|
|

|
Closing this as the problem is identified. Moving conversation to #1530 |
|
Just reporting the landscape now
Seems better! Still can't get past 20 tx per second but at least it is stable. Does not seem to be bottlenecked by IO. Will play more with it, seeing if there is some low hanging fruits. |


{kind=link}
{kind=link}
I am benchmarking the simplest case where Alice pays Bob:
It seems it takes more and more time. I guess auto clean invoice would solve the issue... but still, it should not be linear.
This is one 100 iterations, where each iteration is 16 run of 3 concurrent payments.
The text was updated successfully, but these errors were encountered: