This repository will be updated to include information about DualTKB.
If you want a quick introduction to DualTKB, please read our short description below.
For a more detailed explanation, please check out our arXiv paper DualTKB: A Dual Learning Bridge between Text and Knowledge Base. It is similar to our EMNLP'20 Paper with updated figures.
This work will be presented at the virtual EMNLP’20 conference
Join us at the Gather Session 5D “Information Extraction” on 11/18/2020 at 1pm (UTC-5) US East Coast Time!
The code base was completely rewritten for our new research publications. It is available at ReGen
@inproceedings{dognin-etal-2020-dualtkb,
title = "{D}ual{TKB}: {A} {D}ual {L}earning {B}ridge between {T}ext and {K}nowledge {B}ase",
author = "Dognin, Pierre and
Melnyk, Igor and
Padhi, Inkit and
Nogueira dos Santos, Cicero and
Das, Payel",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.694",
pages = "8605--8616",
abstract = "In this work, we present a dual learning approach for unsupervised text to path and path to text transfers in Commonsense Knowledge Bases (KBs). We investigate the impact of weak supervision by creating a weakly supervised dataset and show that even a slight amount of supervision can significantly improve the model performance and enable better-quality transfers. We examine different model architectures, and evaluation metrics, proposing a novel Commonsense KB completion metric tailored for generative models. Extensive experimental results show that the proposed method compares very favorably to the existing baselines. This approach is a viable step towards a more advanced system for automatic KB construction/expansion and the reverse operation of KB conversion to coherent textual descriptions.",
}
Capturing and structuring common knowledge from the real world to make it available to computer systems is one of the foundational principles of IBM Research.
The real-world information is often naturally organized as graphs (e.g., world wide web, social networks) where knowledge is represented not only by the data content of each node, but also by the manner these nodes connect to each other. For example, the information in the previous sentence could be represented as the following graph:

Graph representation of knowledge is a powerful tool to capture information around us and enables the creation of Knowledge Bases (KBs) encompassing information as Knowledge Graphs (KGs) so computer systems can efficiently learn from.
Being able to process information embedded within knowledge graphs natively is part of IBM Research effort to create the foundations of Trusted AI, where we build and enable AI solutions people can trust.
IBM Research is particularly interested in the task of knowledge transfer from a Knowledge Graph to a more accessible, human-readable modality, such as text. Text is a natural medium for us humans to acquire knowledge by learning new facts, new concepts, new ideas.
In new work being presented at EMNLP’20, Our team of IBM researchers explored how to create a learning bridge between text and knowledge bases by enabling a fluid transfer of information from one modality to another. The approach is bi-directional, allowing for a dual learning framework that can generate text from KB and KB from text.
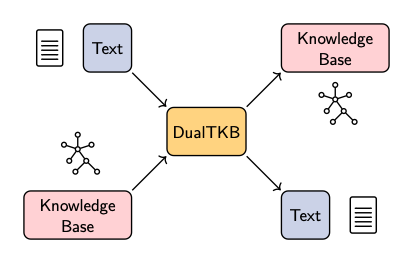
DualTKB at work:

DualTKB is a novel approach to define a dual learning bridge between text and Knowledge Base. DualTKB can ingest sentences and generate corresponding paths in a KB (to tackle this challenging task, we first describe the case of generating one path from/to one sentence).
Since we designed DualTKB to be bi-directional, our approach has the ability to translate (or transfer) to and from modalities natively. Translation cycles can therefore be defined to enforce consistency in generation. For instance, DualTKB can transfer a sentence to the KB domain, take this generated path and translate it back to the text domain. This is key to the dual learning process where translation cycles must return to the original domain with semantic consistency (in our example, we should translate back to a sentence that is either the original sentence, or a sentence semantically very close to it).
These consistency translation cycles were originally motivated by the lack of parallel data for cross-domain generation tasks. By relying on these transfer cycles, our approach handles unsupervised settings natively. In the diagram below, we give examples of all the translation cycles that DualTKB can handle. For instance, from the Text domain, we can transfer to the KB domain, using , and then translate-back to text by using
. We can also do a same-domain transfer by using
.

The proposed model follows an encoder-decoder architecture, where the encoder projects text
or path in a graph
to a common high dimensional representation. It is then passed through a specialized decoder (Decoder A or Decoder B) which can either do a reconstruction of the same modality (auto-encoding)
or
or do the transfer to a different modality
or
.

Traditionally, such systems are trained through a seq2seq (sequence to sequence) supervised learning where paired text-path data is used to enable same- and cross-modality generation. Unfortunately, many of the real-world KB datasets do not have the correspondent pairs of text and path, requiring unsupervised training techniques.
For this purpose we propose to augment the traditional supervised training, when parallel data is present, with unsupervised training when no paired data is available. The overall training process is shown in the diagram below.

The training process can be decomposed into a translation stage (,
) followed by a back-translation stage (
). Inherently, the model can natively deal with both supervised and unsupervised data.
During the training we minimize a total loss:
where the reconstruction loss controls the quality of the autoencoding process:
If supervised data is available, the is included to measure the cross-modality transfer:
And finally, if no supervised data is available, or if the data is partially supervised, we also include the back-translation loss, which ensures that when the transferred modality (text or path) is back-fed into the system and transferred again, the result matches the original input:
We explored the following architectures for the encoder and decoder:
- GRU-GRU, since GRU is a simple, well-known RNN architecture, relatively easy and fast to train
- BERT-GRU, selected to leverage potentially better encoding representation from BERT, a well-known encoder
- Transformer-Transformer, chosen to explore another seq2seq architecture.
A more detailed description of our training method can be found in our paper.
Given the lack of supervised dataset for the task of KB-Text cross-domain translation, one of our contributions is the creation of a dataset based on the widely used ConceptNet KB and Open Mind Common Sense (OMCS) list of commonsense fact sentences. Since ConceptNet was derived from OMCS, we decided to employ fuzzy matching techniques to create a weakly supervised dataset by mapping ConceptNet to OMCS. This resulted in a parallel dataset of 100K edges for 250K sentences. The two datasets we started are:
- ConceptNet dataset for commonsense knowledge representation can be found there: ConceptNet knowledge based completion dataset
- Open Mind Common Sense (OMCS) can be found there: OMCS raw sentences
We are planning to release details and describe the heuristics involved in creating this dataset by fuzzy matching. In the meantime, some information can be found in our paper DualTKB: A Dual Learning Bridge between Text and Knowledge Base.
We compared the performance of DualTKB to published prior-work baselines for the task of link prediction.The table below shows results of MRR and HITS, both well-established metrics for evaluating the quality of link completion. DualTKB compares favorably with the competitors, enabling accurate link completion.

For a more qualitative evaluation of cross-domain generation, we provide examples of transfer from multiple sentences to paths (composing a graph) on the left, and on the right the reverse operation of sentence generation from a list of given paths.

[1] Bishan Yang, Wen-tau Yih, Xiaodong He, Jian-feng Gao, and Li Deng. 2015. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the International Conference on Learning Representations (ICLR).
[2] Théo Trouillon, Johannes Welbl, Sebastian Riedel, Éric Gaussier, and Guillaume Bouchard. 2016. Complex Embeddings for Simple Link Prediction. In ICML, pages 2071–2080
[3] Tim Dettmers, Pasquale Minervini, Pontus Stene-torp, and Sebastian Riedel. 2018. Convolutional2D Knowledge Graph Embeddings. In Thirty-Second AAAI Conference on Artificial Intelligence
[4] Chao Shang, Yun Tang, Jing Huang, Jinbo Bi, Xiaodong He, and Bowen Zhou. 2019. End-to-end Structure-Aware Convolutional Networks for Knowledge Base Completion. In AAAI.
[5] Chaitanya Malaviya, Chandra Bhagavatula, Antoine Bosselut, and Yejin Choi. 2020. Commonsense Knowledge Base Completion with Structural and Semantic Context. Proceedings of the 34th AAAI Conference on Artificial Intelligence.