[Docs] Add Chinese dataflow markdown #2652
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1 +1,90 @@ | ||
| # 数据流 | ||
|
|
||
| 在本章节中, 我们将介绍 [Runner](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html) 管理的内部模块之间的数据流和数据格式约定。 | ||
|
|
||
| ## 数据流概述 | ||
|
|
||
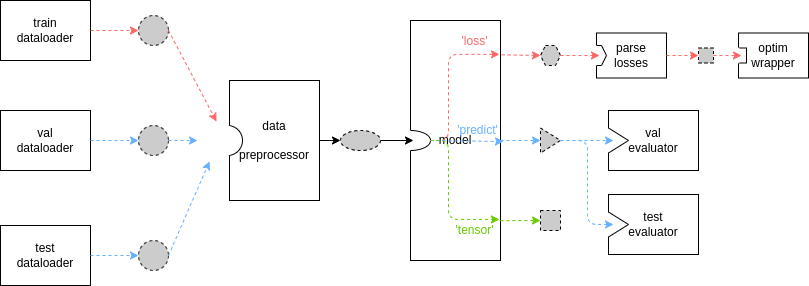
| [Runner](https:/open-mmlab/mmengine/blob/main/docs/zh_cn/design/runner.md) 相当于 MMEngine 中的“集成器”。它覆盖了框架的所有方面,并肩负着组织和调度几乎所有模块的责任,这意味着各模块之间的数据流也由 `Runner` 控制。 如 [MMEngine 中的 Runner 文档](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html)所示,下图展示了基本的数据流。 | ||
|
|
||
|  | ||
|
|
||
| 虚线边框、灰色填充形状代表不同的数据格式,而实心框表示模块/方法。由于 MMEngine 极大的灵活性和可扩展性,一些重要的基类可以被继承,并且它们的方法可以被覆写。 上图所示数据流仅适用于当用户没有自定义 `Runner` 中的 `TrainLoop`、`ValLoop` 和 `TestLoop`,并且没有在其自定义模型中覆写 `train_step`、`val_step` 和 `test_step` 方法时。MMSegmentation 中 loop 的默认设置如下:使用`IterBasedTrainLoop` 训练模型,共计 20000 次迭代,并且在每 2000 次迭代后进行一次验证。 | ||
|
|
||
| ```python | ||
| train_cfg = dict(type='IterBasedTrainLoop', max_iters=20000, val_interval=2000) | ||
| val_cfg = dict(type='ValLoop') | ||
| test_cfg = dict(type='TestLoop') | ||
| ``` | ||
|
|
||
| 在上图中,红色线表示 [train_step](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#train_step) ***([中文链接待更新](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/models.md#train_step))*** ,在每次训练迭代中,数据加载器(dataloader)从存储中加载图像并传输到数据预处理器(data preprocessor),数据预处理器会将图像放到特定的设备上,并将数据堆叠到批处理中,之后模型接受批处理数据作为输入,最后将模型的输出发送给优化器(optimizer)。蓝色线表示 [val_step](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#val_step) 和 [test_step](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#test_step) ***([中文链接待更新](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/models.md#test_step))*** 。这两个过程的数据流除了模型输出与 `train_step` 不同外,其余均和 `train_step` 类似。由于在评估时模型参数会被冻结,因此模型的输出将被传递给 [Evaluator](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/evaluation.md#ioumetric) ***([中文链接待更新](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/evaluation.md#ioumetric))*** | ||
| 来计算指标。 | ||
|
|
||
| ## MMSegmentation 中的数据流约定 | ||
|
|
||
| 在上面的图中,我们可以看到基本的数据流。在本节中,我们将分别介绍数据流中涉及的数据的格式约定。 | ||
|
|
||
| ### 数据加载器到数据预处理器 | ||
|
|
||
| 数据加载器(DataLoader)是 MMEngine 的训练和测试流程中的一个重要组件。 | ||
| 从概念上讲,它源于 [PyTorch](https://pytorch.org/) 并保持一致。DataLoader 从文件系统加载数据,原始数据通过数据准备流程后被发送给数据预处理器。。 | ||
|
|
||
| MMSegmentation 在 [PackSegInputs](https:/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/datasets/transforms/formatting.py#L12) 中定义了默认数据格式, 它是 `train_pipeline` 和 `test_pipeline` 的最后一个组件。有关数据转换 `pipeline` 的更多信息,请参阅[数据转换文档](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/transforms.html)。 ***([中文链接待更新](https://mmsegmentation.readthedocs.io/zh_CN/dev-1.x/advanced_guides/transforms.html))*** | ||
|
|
||
| 在没有任何修改的情况下, PackSegInputs 的返回值通常是一个包含 `inputs` 和 `data_samples` 的 `dict`。以下伪代码展示了 mmseg 中数据加载器输出的数据类型,它是从数据集中获取的一批数据样本,数据加载器将它们打包成一个字典列表。`inputs` 是输入进模型的张量列表,`data_samples` 包含了输入图像的 meta information 和相应的 ground truth。 | ||
|
|
||
| ```python | ||
| dict( | ||
| inputs=List[torch.Tensor], | ||
| data_samples=List[SegDataSample] | ||
| ) | ||
| ``` | ||
|
|
||
| **注意:** [SegDataSample](https:/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) 是 MMSegmentation 的数据结构接口,用于连接不同组件。`SegDataSample` 实现了抽象数据元素 `mmengine.structures.BaseDataElement`,更多信息请在 [MMEngine](https:/open-mmlab/mmengine) 中参阅 [SegDataSample 文档](https://mmsegmentation.readthedocs.io/zh_CN/1.x/advanced_guides/structures.html)和[数据元素文档](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html)。 | ||
|
|
||
| ### 数据预处理器到模型 | ||
|
|
||
| 虽然在[上面的图](#数据流概述)中分开绘制了数据预处理器和模型,但数据预处理器是模型的一部分,因此可以在[模型教程](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/models.html)中找到数据预处理器章节。 ***([中文链接待更新](https://mmsegmentation.readthedocs.io/zh_CN/dev-1.x/advanced_guides/models.html))*** | ||
|
|
||
| 数据预处理器的返回值是一个包含 `inputs` 和 `data_samples` 的字典,其中 `inputs` 是批处理图像的 4D 张量,`data_samples` 中添加了一些用于数据预处理的额外元信息。当传递给网络时,字典将被解包为两个值。 以下伪代码展示了数据预处理器的返回值和模型的输入值。 | ||
|
|
||
| ```python | ||
| dict( | ||
| inputs=torch.Tensor, | ||
| data_samples=List[SegDataSample] | ||
| ) | ||
| ``` | ||
|
|
||
| ```python | ||
| class Network(BaseSegmentor): | ||
|
|
||
| def forward(self, inputs: torch.Tensor, data_samples: List[SegDataSample], mode: str): | ||
| pass | ||
| ``` | ||
|
|
||
| **注意:** 模型的前向传播有 3 种模式,由输入参数 mode 控制,更多信息请参阅[模型教程](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md)。 ***([中文链接待更新](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/models.md))*** | ||
|
|
||
| ### 模型输出 | ||
|
|
||
| 如[模型教程](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#forward) ***([中文链接待更新](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/models.md#forward))*** 所提到的 3 种前向传播具有 3 种输出。 | ||
| `train_step` 和 `test_step`(或 `val_step`) 分别对应于 `'loss'` 和 `'predict'`。 | ||
|
|
||
| 在 `test_step` 或 `val_step` 中,推理结果会被传递给 `Evaluator` 。您可以参阅[评估文档](https://mmsegmentation.readthedocs.io/en/dev-1.x/advanced_guides/evaluation.html) ***([中文链接待更新](https://mmsegmentation.readthedocs.io/zh_CN/dev-1.x/advanced_guides/evaluation.html))*** 来获取更多关于 `Evaluator` 的信息。 | ||
|
|
||
| 在推理后, MMSegmentation中的 [BaseSegmentor](https:/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/models/segmentors/base.py#L15) 会对推理结果进行简单的后处理。神经网络生成的分割logits, 经过 `argmax` 操作后的分割mask和ground truth(如果存在)将被打包到类似 `SegDataSample` 的实例。 [postprocess_result](https:/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/models/segmentors/base.py#L132) 的返回值是是一个 **`SegDataSample`的`List`**。下图显示了这些 `SegDataSample` 实例的关键属性。 | ||
|
|
||
|  | ||
|
|
||
| 与数据预处理器一致, 损失函数也是模型的一部分, 它是[解码头](https:/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/models/decode_heads/decode_head.py#L142)的属性之一。 | ||
|
|
||
| 在MMSegmentation中, `decode_head` 的 [loss_by_feat](https:/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/models/decode_heads/decode_head.py#L291) 方法是用于计算损失的统一接口。 | ||
|
|
||
|
|
||
| 参数: | ||
|
|
||
| - seg_logits (Tensor): 解码头前向函数的输出 | ||
| - batch_data_samples (List\[:obj:`SegDataSample`\]): 分割数据样本,通常包括如 `metainfo` 和 `gt_sem_seg`等信息 | ||
|
|
||
| 返回值: | ||
|
|
||
| - dict\[str, Tensor\]: 一个损失组件的字典 | ||
|
|
||
| **注意:** `train_step` 将损失传递进 OptimWrapper 以更新模型中的权重, 更多信息请参阅 [train_step](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/en/advanced_guides/models.md#train_step)。 ***([中文链接待更新](https:/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/advanced_guides/models.md#train_step))*** | ||
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
add space
在推理后, MMSegmentation --> 在推理后,MMSegmentation
会对推理结果进行简单的后处理 --> 会进行简单的后处理以打包推理结果