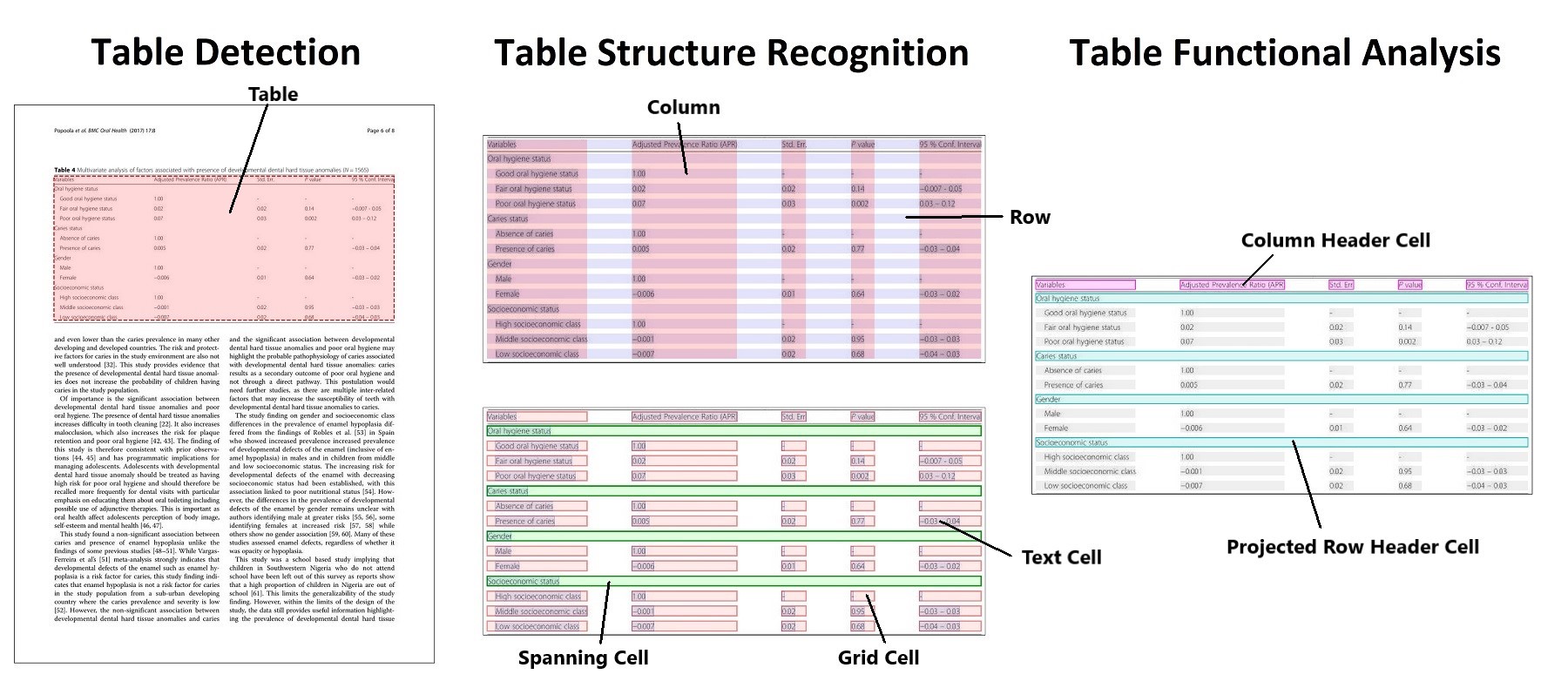
A deep learning model based on object detection for extracting tables from PDFs and images.
First proposed in "PubTables-1M: Towards comprehensive table extraction from unstructured documents".
This repository also contains the official code for these papers:
- "GriTS: Grid table similarity metric for table structure recognition"
- "Aligning benchmark datasets for table structure recognition"
Note: If you are looking to use Table Transformer to extract your own tables, here are some helpful things to know:
- TATR can be trained to work well across many document domains and everything needed to train your own model is included here. But at the moment pre-trained model weights are only available for TATR trained on the PubTables-1M dataset. (See the additional documentation for how to train your own multi-domain model.)
- TATR is an object detection model that recognizes tables from image input. The inference code built on TATR needs text extraction (from OCR or directly from PDF) as a separate input in order to include text in its HTML or CSV output.
Additional information about this project for both users and researchers, including data, training, evaluation, and inference code is provided below.
Run command
pip3 install -r requirements.txtCreate a conda environment from the yml file and activate it as follows
conda env create -f environment.yml
conda activate tables-detrTo download trained model weights on estatement document, run this command
bash download_models.shTo run the inference, you can follow this command:
%cd src/
bash simple_inference.shResult example:
{
"result": [
{
"table_bbox": [
32,
479,
1206,
1550
],
"objects": [
{
"label": "table column",
"score": 0.999552309513092,
"bbox": [
179,
482,
380,
1535
]
},
{
"label": "table row",
"score": 0.9950479865074158,
"bbox": [
43,
614,
1195,
659
]
}
]
}
]
}WIP