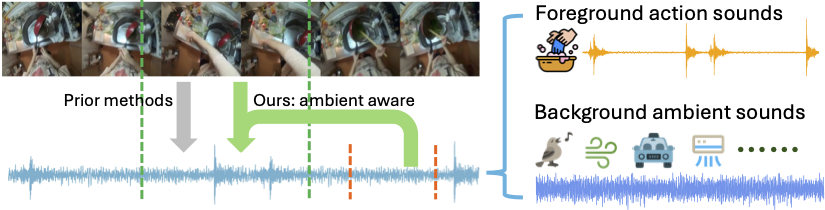
Generating realistic audio for human interactions is important for many applications, such as creating sound effects for films or virtual reality games. Existing approaches implicitly assume total correspondence between the video and audio during training, yet many sounds happen off-screen and have weak to no correspondence with the visuals---resulting in uncontrolled ambient sounds or hallucinations at test time. We propose a novel ambient-aware audio generation model, AV-LDM. We devise a novel audio-conditioning mechanism to learn to disentangle foreground action sounds from the ambient background sounds in in-the-wild training videos. Given a novel silent video, our model uses retrieval-augmented generation to create audio that matches the visual content both semantically and temporally. We train and evaluate our model on two in-the-wild egocentric video datasets Ego4D and EPIC-KITCHENS. Our model outperforms an array of existing methods, allows controllable generation of the ambient sound, and even shows promise for generalizing to computer graphics game clips. Overall, our work is the first to focus video-to-audio generation faithfully on the observed visual content despite training from uncurated clips with natural background sounds.
Project page: Action2Sound
- Evaluation Code ☑️
- Pretrained weights ☑️
- Training code ☑️
- Install the necessary packages by running the following commands within the repo:
conda env create -f environment.yml
conda activate action2sound
- You may additionally need to install Speechmetrics and SRMRpy
Prepare the dataset following this link.
Our model weights and other necessary pre-trained models can be found on Huggingface.
The pretrained models should be organized in the following structure:
data
├── logs
│ └── ego4d
│ └── audiocond
│ └── checkpoints
│ └── epoch=000007.ckpt
└── pretrained
├── av.pth
└── sd-v1-4-full-ema.ckpt
- Training
python main.py --base configs/ldm/ego4dsounds.yaml --train --name audiocond --num-nodes 1 --gpus 0,1,2,3,4,5,6,7 --epoch 8 --scale_lr False --batch-size 90 --pretrained-model data/pretrained/av.pth --pool-patches max model.params.audio_cond_config.neighbor_audio_cond_prob=1 --audio-cond rand_neighbor
- Evaluation
Add the following flags to the training command to evaluate and compute metrics:
--test --eval-ckpt X
- Inference
Add the following flags to the training command to run the model for inference and generate audio files:
--test --eval-ckpt X --visualize --demo-dir /path/to/videos
If you find the code, data, or models useful for your research, please consider citing the following paper:
@article{chen2024action2sound,
title = {Action2Sound: Ambient-Aware Generation of Action Sounds from Egocentric Videos},
author = {Changan Chen and Puyuan Peng and Ami Baid and Sherry Xue and Wei-Ning Hsu and David Harwath and Kristen Grauman},
year = {2024},
journal = {arXiv},
}
This repo is licensed, as found in the LICENSE file.